<![CDATA[Esa-Matti Suuronen]]>2013-06-18T13:41:44+03:00http://esa-matti.suuronen.org/Octopress<![CDATA[Asynchronous module loading with Browserify]]>2013-04-15T10:00:00+03:00http://esa-matti.suuronen.org/blog/2013/04/15/asynchronous-module-loading-with-browserifyThis is a sequel for the Journey From RequireJS to Browserify post.
After publishing the previous post I got a lot of feedback saying that
Browserify can’t do asynchronous module loading. Since that’s something I’d
like to have with Browserify too I started looking on how to do it and after
couple of pullrequests and one published npm
module later I’m happy to say it’s very much possible now!
Background
Basically asynchronous module loading can be done just by creating multiple
bundles with Browserify and loading them with a script loader of your choosing.
There is one in jQuery or if you don’t like jQuery there
arequiteafewstandaloneonesout there.
Loading shims for old browsers
This is a simple use case and it has almost nothing to do with Browserify. For
example if we are using Function.prototype.bind in our app and we want to
load es5-shim if the browser is missing the implementation:
index.js
123456789101112
if(Function.prototype.bind){// Just require the main module if the browser// has Function.prototype.bind implementationrequire("./main");}else{// If not load the es5-shim with a script loader and// require main after it has loadedjQuery.getScript("./vendor/es5-shim.js",function(){require("./main");});}
Conditional bundle loading
We might have different bundles for different browsers. Often on modern
browsers we can rely on the native implementations and skip the Javascript
shims or polyphills that are required for the older ones. We could for example
inlude a custom lightweight jQuery build to our “modern browser” bundle or
go little extreme and use Zepto in place of jQuery for modern browsers like we
do here.
To detect modern enough browsers for Zepto we check for
document.querySelector implementation.
To do this we need to build simple lightweight entry point with a script loader
and two versions of the main bundle. One with Zepto and one with jQuery.
build.js
123456789101112131415
varbrowserify=require("browserify");varindex=browserify("./index");varjquery=browserify("./main");varzepto=browserify("./main");// The main bundle has require calls to both jQuery and Zepto.// So remove Zepto from the jQuery bundle:jquery.external("./vendor/zepto");// and jQuery from the Zepto bundle:zepto.external("./vendor/jquery");index.bundle().pipe(fs.createWriteStream("./bundle/index.js"));zepto.bundle().pipe(fs.createWriteStream("./bundle/main-zepto.js"));jquery.bundle().pipe(fs.createWriteStream("./bundle/main-jquery.js"));
In index.js we just detect which one we want to use and load it:
index.js
12345678910111213
// Since we don't have jQuery.getScript here we use an// lightweight alternative called $script.js. npm: scriptjsvar$script=require("scriptjs").$script;// We set a global flag indicating which one we are using.// We use this later to detect which one we can require.window.USE_ZEPTO=!!document.querySelectorAll;// The both main bundles have an entry points (main.js) so we// only need to load them and the code will be executed soon// as it is added to the DOMif(window.USE_ZEPTO)$script("bundle/main-zepto.js");else$script("bundle/main-jquery.js");
In our app code we need to abstract the require calls to jQuery and Zepto to
make it smooth:
jquery-or-zepto.js
12345678910
// Neither one, jQuery or Zepto, does CommonJS exports// so grab them from the globals after requiringif(window.USE_ZEPTO){require("./vendor/zepto");module.exports=window.Zepto;}else{require("./vendor/jquery");module.exports=window.jQuery;}
And in app code just use var $ = require("./jquery-or-zepto"); to get the
correct one depending on the bundle we loaded.
Lazy loading rarely used parts
Now this is where things get really interesting.
Lets say our app has some graph view which requires a large graphing library
and we want to load that library and related code lazily only when the user
actually uses the feature like this:
To do this we have to remove the ./graph-view and its dependencies from the
main bundle. Here’s where my module, externalize, comes to help.
We create a second Browserify bundle which is a subset of the main bundle and
use the externalize function to remove code from the main:
build.js
123456789101112131415161718
varfs=require("fs");varbrowserify=require("browserify");varexternalize=require("externalize");// Main bundle has main.js as the entry pointvarmain=browserify("./main");// Graph bundle does not have an entry point, but it has// `./graph-view` as requireable modulevargraph=browserify().require("./graph-view");// Use externalize to remove graph bundle code from the mainexternalize(main,graph,function(err){if(err)throwerr;// After externalizing the bundles can be written to filesmain.bundle().pipe(fs.createWriteStream("./bundle/main.js"));graph.bundle().pipe(fs.createWriteStream("./bundle/graph.js"));});
Now just include ./bundle/main.js to the page and ./bundle/graph.js will
be loaded lazily when needed.
Checkout the externalize readme file for more information.
Putting it all together
I’ve uploaded a more real worldish example on github pages using
the techniques presented here. It will also serve as a decent Backbone.js and
Handlebars example with Browserify. It’s heavily commented so it should be
easy to follow even if you don’t know/care anything about Backbone or
Handlebars.
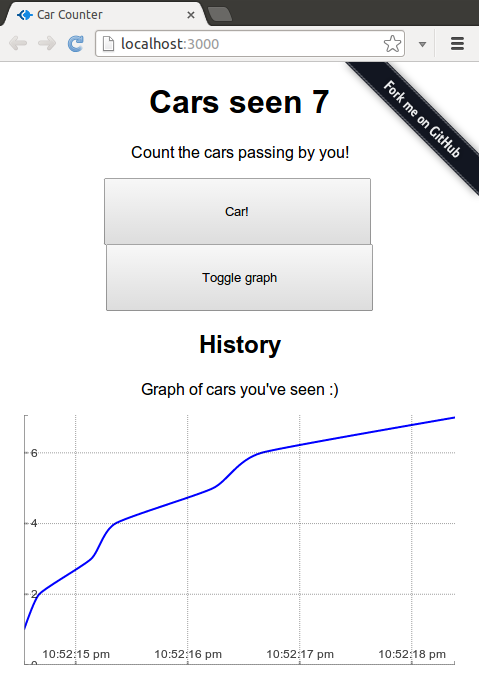
Open up devtools from your browser and look at the network tab to see what
happens when you hit to “Toggle graph” button for the first time.
I encourage you to read the source code of the example in following order:
Take a look at their sizes and skim through what they contain
Before going crazy with it
Before slicing up your Browserify bundles you should really sit down and think
through whether this is really required for your app. For example if you add a
largish image to your app it might easily dissolve all the benefits you gained
by slicing the bundles. Even a single 100kb image will translate to a quite big
chunk of minified and gzipped Javascript code. And because this can get very
complex if you go crazy with it you should make sure it is worth it.
Happy hacking!
]]><![CDATA[Journey from RequireJS to Browserify]]>2013-03-22T13:37:00+02:00http://esa-matti.suuronen.org/blog/2013/03/22/journey-from-requirejs-to-browserifyLately I have been very frustrated with RequireJS. I have a feeling that I
have to fork almost every third party library I’m using in my projects. So I
started investigating Browserify as an alternative. Here’s what I found.
RequireJS
First I want to little bit explain why RequireJS bugs me. The main reason is
the mess with the AMD define functions calls in various libraries. Some do
them and some don’t. That’s usually ok because you can easily shim the
libraries but when you have dependencies between the third party libraries the
shit starts hitting the fan.
Disappearing globals
My latest frustration was with the Flotr2 graphing library. I decided to use
the regular build with the intention of shimming the Flotr global because the
AMD build was so much older. But there was a nasty surprise waiting for the
RequireJS users. Flotr2 depends on a library called Bean which is bundled into
Flotr2 and it just expects to find the Bean library from the global namespace.
Ok, but the Bean library itself has an UMD style AMD definition which means
that when it detects an AMD define function it uses it and skips the creation
of the global which results in broken Flotr2. It really bums me out to fork
libraries and remove AMD defines to make them work with AMD!
update!
Handlebars plugin and the build step
Another pain point has been the require-handlebars-plugin. It’s really
complex to configure to work properly with the r.js builds. It requires forked
versions of Handlebars, Underscore and json2 libraries. It also forces you to
include some i18n solution which collided with ours. Not fun. I just wanted to
use Handlebars with precompilation (In the end I ended up writing my own
Handlebars loader plugin).
These are just few of the issues I’ve had with RequireJS. Not really anything
blocking but there is just always some annoyances especially with build the
step and it doesn’t help that it doesn’t give proper error messages when
something goes wrong.
Enter Browserify V2
I’ve always preferred the node.js style module syntax (module.exports) over
the AMD style. It’s just simpler and easier to deal with. Also I haven’t gotten
any real benefits from the asynchronous part of AMD. So I’m very open to
replace it with simpler synchronous requires. And now with the new version 2 of
Browserify by substack it seems to more simpler than ever to use them in the
browsers too.
So I made a list of few features I need to consider before jumping into it:
Debugging: I don’t want to see just one big bundle in the browser
Using libraries with globals
CoffeeScript precompiling
Handlebars precompiling
Multiple versions of the same dependency
Debugging
Well this one was easy. Just build the bundle with --debug flag
$ browserify --debug main.js > bundle.js
and Browserify will inline source maps into the bundle and then just fire up
Chrome with source maps enabled from developer tools and it will display the
original files as they where separate files.
But currently this seems to work only with Chrome. In others you get just a
huge bundle of Javascript. Source maps are coming to Firefox but I wouldn’t put
my hopes up for IE…
Using libraries with globals
Lets face it. The browser world is just not going to adopt any module system
unanimously any time soon. We just have to work with libraries exposing them as
globals on the window object. I just want be able to use them without forking
them.
Browserify does somewhat decent job about this. If you require a random
Javascript file exposing globals the require call will return undefined but
after that you can just access the globals. Only requirement seems to be that
the library exposes itself explicitly to the window object. If it uses a
var statement to declare the global then you get into trouble. In Browserify
that global will be hidden inside the module closure. Also this seems to be
bound to some internal dependency array of Browserify so libraries exposing
global to it need some special handling too. update!
Shims
In RequireJS you can configure shims for the globals. With shims you can use
the globals just they had the AMD define without touching the library code. It
appears that you can do the same in Browserify just by writing simple wrapper
modules.
Example with jQuery:
jquery.shim.js
12345
// jQuery does not export itself as node.js/CommonJS modulerequire("./jquery.js");// but after the require we can just export the jQuery// global from this modulemodule.exports=window.jQuery;
And then for example in jQuery plugin module you can just do:
Also in a Flotr like cases note where you have a library
expecting a global but you only have it as a non global module you can just put
the global back in the shim:
Substack himself has written a CoffeeScript plugin for Browserify called
coffeeify. Since he isn’t a CoffeeScript user he is looking for maintainers
for the plugin. Nevertheless the plugin works surprisingly well.
It is used by installing it locally to a project and calling browserify with
a --transfrom flag:
By working surprisingly well I mean this fun little feature:
Source maps!
Handlebars precompiling
Well, here Browserify had nothing to offer out of the box but I took it as an
opportunity to get my self familiar the Browserify transform plugin API and
about an hour later had it working:
When compared to RequireJS plugin API this was a really nice experience. A lot
less confusing: No need to figure out how to do ajax in development, file
system reading during build build or how to work with custom APIs. Just the
familiar node.js transform streams here. I like it a lot.
Multiple versions of the same dependency
As Browserify uses npm as its package manager you should be aware how npm
pulls in dependencies. If two modules have a same dependency but on a
different versions it will download two copies of this dependency and those
will be put into the Browserify bundle too! Luckily npm is smart enough to
combine those dependencies if their semver version strings are compatible.
This means that if you use for example Underscore in your project root it must
be compatible with every subdependency of your dependencies to get only one
copy of Underscore to your Browserify bundle. But I do think this is a nice
feature because then you don’t get into any trouble using libraries with
conflicting dependencies. You only get few more bytes. It’s just something to
be aware.
Conclusion
This journey is still on going but I think will try using Browserify in my next
project or convert some old one from RequireJS.
To conclude here’s a list of pros and cons when moving from RequireJS to
Browserify.
Pros
Always bundling. No running into build problems later on.
Can use cool things from node.js.
Simpler syntax: module.exports = ... FTW!
npm at your disposal.
Sharing modules with node.js is no brainer
Source maps for CoffeeScript. Thou RequireJS will probably get those
soon too.
The plugin API is awesome.
Cons
Always bundling. Debugging old browsers can be a pain.
Must use a watcher tool for the builds. RequireJS can work purely in the
browser
Some people might not want browser only libraries to npm. I’m not sure
what’s the node.js/npm authors’ stand on this
update!, but nevertheless with browserify you are
not bound to npm. Nothing should prevent you from using CommonJS modules
from Bower for example.
Documentation could be better. Lots of things are assumed that you know
already from node.js. I hope this blog post helps a little bit.
No community other than the node.js community. I’d like to see a mailing
list and an IRC channel.
Next
There are still few thing I want to investigate. If browser only modules are
ok in npm: How can I use images and CSS from a npm module? CSS could done
with a transform plugin and some runtime code which appends it to DOM, but how
to get images from it especially if I’m not using node.js as my backend?
Another interesting area to investigate would be component modules. They
use the CommonJS syntax but I have no idea whether they can be used from
Browserify.
Drop a comment if you know anything about these. Thanks!
Note: In reality the Flotr2 distribution is unusable in Browserify too
because it contains multiple CommonJS exports in a single file which is
inherently incompatible with the CommonJS specification to start with.
Update 1: Browser only modules are ok in npm. See the comments.
Update 2: It
appears you can
restore the global from RequireJS too.
Update 3: this works like you would expect in node now.
]]><![CDATA[Mastering nested views in Backbone.js]]>2012-12-10T22:25:00+02:00http://esa-matti.suuronen.org/blog/2012/12/10/mastering-nested-views-in-backbone-dot-jsDuring the last year or so I have been building quite a few apps on top of
Backbone.js. The reason for choosing Backbone.js was the fact it’s fairly low
level. It does not get in my way when I want to integrate some random crappy
jQuery plugings or swap Ajax backend to Websockets in to my apps etc. Also it
doesn’t isolate me to inside some framework wonderland jail. I really had to
learn how to work with the DOM and how to arrange my code. This is good in the
since it has given me good foundations how things generally work if I ever want
to venture into some other frameworks.
But there is a downside to all this low levelness. With certain aspects you are
really left alone by the framework. For me the hardest part was how to handle
nested views.
Backbone.ViewMaster
I think I’ve found some good patterns on how to handle them. Originally I
wanted to just write a blog post about them, but more I looked my code I
realized it would be better as a library, because they were not that trivial in
the end.
This not by any means unique. There are several libraries that can help you
with nested views. I would guess the most notable ones are
backbone.layoutmanager and Marionette.js. But I wanted something simpler. So
here’s Backbone.ViewMaster:
It is just a single Backbone.js View which can be used as the base view when
building Backbone.js apps. It tries to be more than just a library as it
encourages on writing decoupled and reusable views. Read the tutorial to get
gist of it.
]]><![CDATA[How to Use Guard::LiveReload With Octopress]]>2012-11-04T13:30:00+02:00http://esa-matti.suuronen.org/blog/2012/11/04/how-to-use-guard-livereload-with-octopressDuring the development of Opinsys Labs site I had to bit hack on
Octopress/Jekyll to make Guard::LiveReload to reliably.
]]><![CDATA[Bringing HTML5 to the Desktop With AppJS]]>2012-11-04T13:29:00+02:00http://esa-matti.suuronen.org/blog/2012/11/04/bringing-html5-to-the-desktop-with-appjs
]]><![CDATA[Blogging at Opinsys Labs]]>2012-11-04T13:16:00+02:00http://esa-matti.suuronen.org/blog/2012/11/04/blogging-at-opinsys-labsSince I also blog actively to our company blog Opinsys Labs and the
content is highly similar to what I usually blog here. I will link some of
those post to here from now on.
If you’re more interested on what we do at Opinsys follow our Twitter accounts
@OpinsysLabs and @Opinsys (mostly finnish) too.
]]><![CDATA[Improving console.log for Node.js]]>2012-09-30T22:33:00+03:00http://esa-matti.suuronen.org/blog/2012/09/30/improving-console-dot-log-for-node-dot-jsNode.js gives you four methods for logging stuff console.log(),
console.info(), console.warn(), and console.error(). These could go
pretty far, but unfortunately they fall bit short since their output does not
give any indication which method was used for logging except for the output
stream. Which in my opinion is bit confusing. But I do like their API.
They can do printf like formating, pretty printing objects and they can even
handle objects with circular references.
So I’ve written a little module called clim (Console.Log IMproved) which
gives some superpowers to console.log and friends.
Usage
You can shadow the original console or monkeypatch it once and for all
1234567
varclim=require("clim");// Just shadow itvarconsole=clim();// or monkeypatch it!clim(console,true);
Now you can use console.log just like before, but the output is more detailed:
1234
console.log("message with log");console.info("message with info");console.warn("message with warn");console.error("message with error");
1234
Sun Sep 30 2012 23:06:24 GMT+0300 (EEST) LOG message with log
Sun Sep 30 2012 23:06:24 GMT+0300 (EEST) INFO message with info
Sun Sep 30 2012 23:06:24 GMT+0300 (EEST) WARN message with warn
Sun Sep 30 2012 23:06:24 GMT+0300 (EEST) ERROR message with error
Also now all the methods write to stderr for the sake of consistency. By
default log and info writes to stdout and warn and error to stderr, but
this causes some pains when redirecting logs to a single file. Log order might
be messed up depending on IO buffering etc.
Of course keep in mind that this might break your unix style app which uses
stdout to communicate outside if you depend on console.log() being the print
statement of Node.js. Rather use process.stdout.write(). It is more explicit
and gives you more control.
Background
The main idea behind this module is to keep the original API of
console.log(), because then it is possible to just drop it in a project
without any refactoring. If you encouter any inconsistencies with with it
please file a bug.
clim also exposes few hooks that can be used to customize its behaviour. You
can modify the date string, change log target from stderr to back stdout or
even to a database, add default prefixes to console objects and inherit from
them. For more details view the project page on Github:
]]><![CDATA[Creating KISS daemons in Linux]]>2012-07-22T13:53:00+03:00http://esa-matti.suuronen.org/blog/2012/07/22/creating-kiss-daemons-in-linuxDaemonizing processes in Linux and running them on boot is a very easy task in
theory, but the variety of different Linux distributions tend to make it
incredible hard sometimes. So here’s my take on Daemonizing processes without a
headache.
Background
When starting a process on boot there are usually few requirements I need
Drop privileges from root
Ensure safe umask
Redirect stdout/stderr to a log file
Set current working directory
Set environment variables
Write a pid file
And finally daemonize the process
These all are fairly trivial tasks to implement in the actual application, but
also these are the same for every app. I like to keep things DRY. When I’m
creating for example some simple prototype application in Node.js I really
don’t care to think about which logging framework to use or how to do a double
fork in a environment which don’t even have a fork call to begin with.
I’m usually working with Debian and Ubuntu based distros. They both have
a init system which can be used to accomplish these requirements.
Debian uses /etc/init.d/ style scripts and Ubuntu uses Upstart which is
actually somewhat usable. Here’s my Upstart config for Redis for
example, but that’s not usable in Debian of course. Debian gives you a skeleton
script in /etc/init.d/skeleton which can be used to create a daemon on boot
up. That’s 159 lines long! Pretty complex for such a simple task I’d say.
Alternative
Luckily there are alternative tools for daemonizing processes. One of the
simplest ones I’ve encountered is called daemon. This tool has been
around for a while, but I’ve just found out about it. I think the name makes it
kinda hard to stumble upon…
It’s easily installable via apt-get
# apt-get install daemon
Then it is just matter of running the command on boot up. I don’t usually care
about the run levels so I just put it in /etc/rc.local which is the last
script executed during Debian and Ubuntu boot process.
My daemon setup for Node.js servers is usually something like this:
It’s Fairly straightforward. Just make sure that the pid and log directories
are writable by the user. The --inherit switch is only required when defining
custom environment variables with --env so that you don’t loose previously
defined environment variables such as PATH. There is no mention of umask in
this command, because daemon sets it to 022 by default to prevent creation of
group or world readable files. Checkout the man page for details.
]]><![CDATA[Grocery Store Analogy for Evented Web Servers]]>2012-06-03T18:33:00+03:00http://esa-matti.suuronen.org/blog/2012/06/03/grocery-store-analogy-for-evented-web-serversToday I was trying to explain the differences between threaded and evented web
servers to a friend on a high level. Usually the threaded model is explained
with a grocery store analogy and I started to wonder how that analogy could be
extended to explain the evented model too.
Threaded model
Lets revise the grocery store analogy for the threaded web servers first.
Grocery store is the web server, cashiers are the threads and customers are the
incoming requests.
During a late afternoon when everybody is leaving work and going for grocery
shopping the store will be filled with customers. For the store to work
properly the store owner has to hire multiple cashiers to cash the customers
concurrently in order to keep them from waiting in long lines. Web servers
spawn multiple threads to serve requests concurrently to keep users from
waiting pages to load. Hiring cashiers cost money as spawning threads cost
memory and CPU cycles.
Evented model
In the evented model the web server has only a single thread. How a store with
single cashier could function in a rush hour?
The cashiers use most of the their time scanning bar codes as threads use most
of the their time waiting for I/O in threaded web servers. In some modern
stores the customers scan the products themselves while picking them to their
baskets. This means that there is no limit how many products can be scanned
concurrently. Same goes for evented web servers. The thread is not waiting for
any I/O. It just does the real computing work as the cashier does only cashing
of the customers. This is very efficient.
This is of course has some drawbacks. A single troublesome customer can block
the entire checkout line for all the customers. This is true for evented web
servers too. It will go to bankruptcy if Mr. Fibonacci is let in to the store
to occupy the only cashier with long computations. The single thread cannot
respond to any other requests if it is busy computing something.
Luckily this is not usually the case with web servers and if the web
application really needs to do some intensive computations the work must be
handed to some other worker process. This way the thread can keep responding to
the requests in a timely fashion. Like in the store, the cashier cannot go of
doing something else for long periods of time without creating long lines. He
will need someone to help on those tasks.
Evented systems can be more efficient, but you have to take greater care of
what you let run in it.
Conlusion
While this is not a perfect analogy, but I do like how this explains some of
the drawbacks too. Some evented systems (read Node.js) get way too much hype
for just being fast without considering the gotchas and the real benefits
they bring in, but that’s a whole another blog post.
I hope this helps some others to grasp the evented model too.
]]><![CDATA[Rendering Javascript Templates Without Rendering]]>2012-05-28T22:56:00+03:00http://esa-matti.suuronen.org/blog/2012/05/28/rendering-javascript-templates-without-renderingFor a long time client-side templating languages has somewhat bothered me.
Since they all take strings as input and re-renders those to DOM elements on
every small change you want to make. That has always sounded bit silly to me.
Why not just create the DOM tree once and then just manipulate the bits you
want to be changed?
Well in practice that’s lots of work even with help of jQuery. Surprisingly it
appears that templating languages are not invented without a reason. Although
there are several templating languages that are made for DOM only manipulation,
but for reason or another I haven’t liked any of them until I was told to try
Transparency made by Jarno Keskikangas on the Finnish Javascript
channel #javascript.fi on IRCnet.
It gives a simple semantic data binding API which makes it easy to do similar
transformations to DOM as you would do with regular templating languages like
collection rendering, but without actually rendering any strings to DOM
elements or cluttering them with some micro programming language. Transparency
templates are just DOM elements filled with data and nothing more. The logic
stays in the Javascript code.
Using with Backbone.js
Since it not directly obvious how use it with Backbone and similar client-side
frameworks efficiently I’ll give a simple example here.
First you must have some base DOM elements which can be used as templates:
These can be anywhere in the DOM. Just add some CSS to hide it:
123
#templates{display:none;}
Next we will create a simple Backbone View which will demonstrate Transparency
usage with Backbone. It just displays a name and some random values.
12345678910111213141516171819202122232425
varDataViewer=Backbone.View.extend({// Cache the template selector for all DataViewer Views.baseEl:$("#templates .data"),constructor:function(){Backbone.View.prototype.constructor.apply(this,arguments);// Get View element for this view instance just by cloning// the object from the DOM.this.setElement(this.baseEl.clone());// Render on every model change.this.model.on("change",this.render,this);},render:function(){// Let Transparency to render the model data. This is very// efficient since it does not create new elements (except when// looping collections), but just fills the existing DOM with// given data.Transparency.render(this.el,this.model.toJSON());}});
Note how Javascripty this is. The view element is got just by copying the
existing DOM objects like you would do with normal Javascript objects. You
copy an object and then extend it. You could do even some template inheritance
with this.
The view is used like any other Backbone View:
1234567891011
varmodel=newBackbone.Model({name:"Mouse Position"});varmousePosition=newDataViewer({model:model});// Put it to the DOMmousePosition.render();$("#content").append(mousePosition.el);// Put some random data to our model$(document).mousemove(function(e){model.set({x:e.pageX,y:e.pageY});});
With Transparency there is one feature or gotcha you must be aware of. The
state of the view.el element is not completely reset between render calls.
This can be an advantage in some situations. For example you could do some
additional manipulation with jQuery to it which is not lost between render
calls. But if you need to reset it you can just reclone the base element again.
Here’s a fully working fiddle of this example
for you to play with.
This sounds very promising to me and I’m going to try it in some project when I
get the chance.
]]><![CDATA[Slimux - tmux Plugin for Vim]]>2012-04-19T19:21:00+03:00http://esa-matti.suuronen.org/blog/2012/04/19/slimux-tmux-plugin-for-vimLately I’ve gotten really in to tmux and I’ve been looking for ways to
integrate it to my Vim workflow. As result I ended up creating this Vim
plugin.
If you are unfamiliar with tmux, it’s best described as alternative to GNU
screen or Tiling Window Manger for console application. For fast start I can
recommend a book from The Pragmatic Bookshelf - tmux: Productive Mouse-Free
Development.
The plugin takes its inspiration from Emacs Slime as well as from other similar
Vim plugins.
The idea behind it is to make interaction with Read Eval Print Loops (REPL)
easier. You can select for example portion of Ruby code execute it in
Interactive Ruby (irb) with just one command. Also another goal is to make
running of build and test commands a breeze.
Usage goes like this :
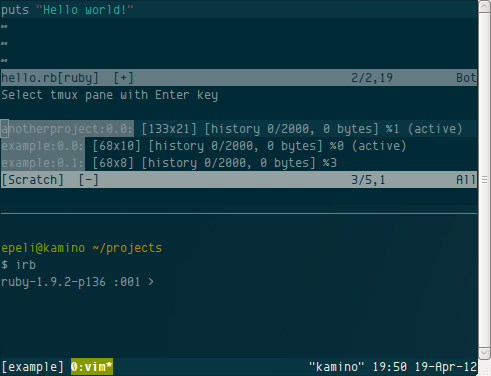
Create a tmux pane and start your REPL in it
Select some code and hit the keyboard shortcut (you must configure this)
Slimux now prompts the pane from you:
Here you list of all your tmux panes. The syntax is read like this
1
[session name].[window index].[pane index]
Slimux will then remember that selection and won’t ask it again unless you
explicitly want to reconfigure it. After that Slimux sends the code to the REPL
and executes it.
Yes, there are quite a few tmux plugins for Vim already and this plugin got
started pretty much by accident. I started by fixing
somebugs from
vim-slime. One thing I wanted
for it was an interactive prompt for tmux pane selection. Typing the target
pane manually is kinda pain. I started working on that feature on a empty
plugin and soon I realized that it was actually easier to grab features from
vim-slime to my plugin than to merge my work back to upstream. That was mainly
because vim-slime supports GNU screen which I don’t care at all. Every this
heavy GNU screen user should just upgrade to tmux anyway.
Then there is Vimux which on the surface seems to do every thing as Slimux,
but there where few annoyances for me. It takes too much control of tmux. It
creates the tmux pane for you where you must run your commands/REPLs. I want to
manually configure my tmux. Slimux allows you to manually select the tmux pane.
Very often I want to run the REPL or commands in whole another tmux
session so that I can put it to my second monitor. This also means that Slimux
works just fine with GVim.
Another issue is that Vimux doesn’t have hooks to preprocess code by its type
before sending it to REPL. For example you have to the remove extra line breaks
from Python code to make it work with its REPL.
Also I just kinda wanted learn some Vim Scripting and this is my first proper
Vim plugin I’ve written. Feedback is really appreciated.
]]><![CDATA[How to Write CoffeeScript Efficiently]]>2011-11-28T20:07:00+02:00http://esa-matti.suuronen.org/blog/2011/11/28/how-to-write-coffeescript-efficientlyI have found few tricks that makes writing CoffeeScript more efficient and fun,
especially when learning it and I’d like to share it with you.
These tricks are for Vim, but the ideas can be carried out to other editors as
well. I know that at least the TextMate CoffeeScript Bundle can do some of
these.
Basics
Let’s get the basics out of way. Get syntax hilighting from
vim-coffee-script plugin
and automatic syntax checking from
Syntastic. These will
take you a long way, but with CoffeeScript we can do more.
Reading compiled code
Especially when starting out with CoffeeScript you are not always sure what the
snippet you are reading or even the code you just wrote does. Chances are that
you already know Javascript so we can use that to our advantage.
vim-coffee-script makes that incredibly easy.
Lets take following snippet that might be confusing to CoffeeScript newbies:
1
{@foo}=bar
With vim-coffee-script you can just select the snippet in Visual Mode and type
:CoffeeCompile which will open up a new scratch buffer with a compiled
version of the snippet which will clearly tell what this syntax in CoffeeScript
means. You can use this to verify that you understood the CoffeeScript syntax
by using your Javascript knowledge!
I recommend creating a shortcut for this. It’s so useful. Put this to your
.vimrc:
This allows you to invoke the compiler with Leader-key + c. The leader key is
backslash by default, but usually it is redefined to comma.
Stack Traces
I don’t like manually compiling CoffeeScript files for my Node.js apps. Instead
I use the coffee command directly or use plain js wrapper app that starts my
CoffeeScript apps. This is clean and simple, but can be painful when you get an
exception. There is a stack trace, but it refers to the compiled Javacript file
which does not exist! You could look up the original CoffeeScript file and try
to guess what line the stack trace means by looking variable names or manually
compile the file when exception occurs. Not so fun.
vim-coffee-script to the rescue!
When you execute the CoffeeCompile Vim command in Command Mode you will get
the whole file compiled into the scratch buffer. In that you can scroll the
line referred by the stack trace and see what code exactly rose it. This is
bit clumsy since normally you can jump to a certain line by typing :<number>.
We can do better! Put this to .vimrc:
1
command-nargs=1CCoffeeCompile|:<args>
And then try typing :C<number>. Whoah! This takes you to the given line
number in the compiled Javascript of the CoffeeScript file you are editing.
Using it is just one character longer than normally jumping lines!
]]><![CDATA[Python-like Decorators in CoffeeScript]]>2011-10-06T21:10:00+03:00http://esa-matti.suuronen.org/blog/2011/10/06/python-like-decorators-in-coffeescriptI really like decorators in Python and I sometimes miss them when working in
other languages. Today at work it hit me when I was working on a CoffeeScript
project. It is really easy to implement Python-like decorators cleanly in
CoffeeScript.
If you are not familar what decorators are in Python you should skim through
this and
this.
In short they are a nice syntax for wrapping functions/methods with other
functions in Python.
Decorators in Python
Here’s an example usage of Python decorator. Let’s pretend that this is a
class for reading values from some device. It will give us values between 0 and
100, but in this app we want put a roof for the values it gives. We can create
a decorator that limits the values given by the getter.
Decorator in Python (decorator_example.py)download
#!/usr/bin/env python# Our magic deviceimportrandomdefroof(amount):defdecorator(method):defwrapper(*args):value=method(*args)ifvalue>amount:returnamountelse:returnvaluereturnwrapperreturndecoratorclassDevice(object):@roof(50)defget_value(self):# Read value from the devicereturnrandom.randint(0,100)if__name__=='__main__':reader=Device()foriinrange(10):printreader.get_value()
Decorators in CoffeeScript
So that was an advanced configurable decorator for Python. Lets see how
CoffeeScript handles the same situation.
Decorator in CoffeeScript [] (decorator_example.coffee)download
Wow! That is a lot less syntax and no extra nesting!
This really shows how powerful anonymous functions and implicit returns are in
CoffeeScript. Also the usage syntax would not be so clean if CoffeeScript
didn’t have ability to call functions without the parenthesis.
The usage syntax is though better in Python, because you can stack decorators
cleanly with it.
Stacking decorators in Python
12345
classDevice(object):@roof(50)@floor(10)# Checks the bottom of the valuedefget_value(self):returnrandom.randint(0,100)
In CoffeeScript must put them after each others which can get nasty if you have
many decorators.
But wait! There were no specific decorator syntax in Python in the old days.
One could apply decorators just by calling it to the target and replacing the
original method.